KID : Data Quality
KID professionals will help institute a quality discipline within the organization’s processes and information delivery architecture. This entails active management of data content throughout its life-cycle by deploying the appropriate processes and structures to collate, profile, validate, aggregate, match, merge, de-duplicate, enrich, consolidate, quality-assure, store and distribute data.
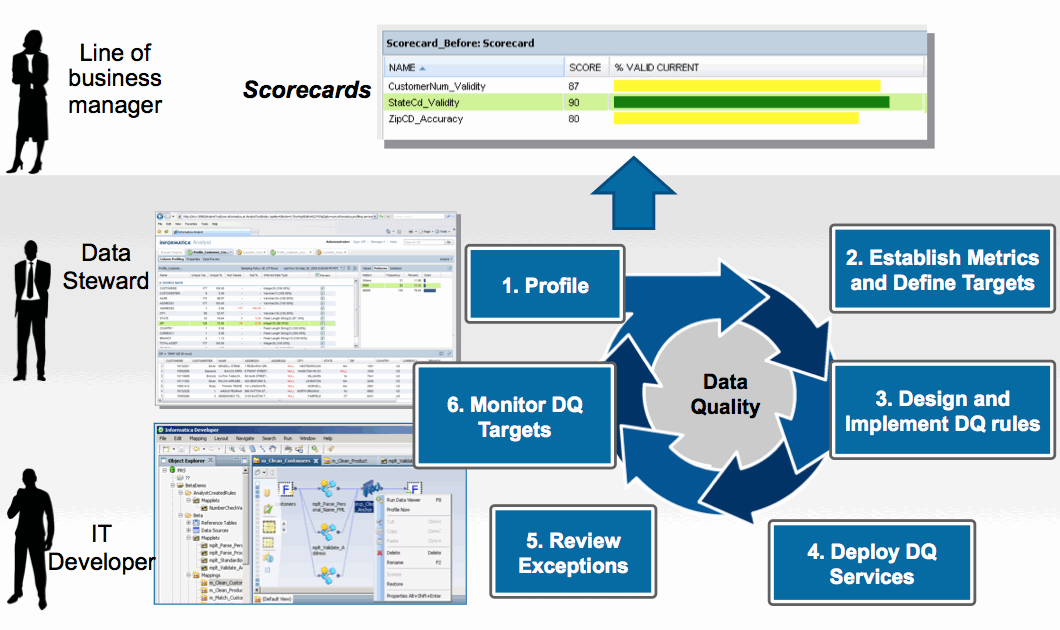
We follow the following methodology:
Data profiling - initially assessing the data to understand its quality challenges
Data standardization - a business rules engine that ensures that data conforms to quality rules
Geocoding - for name and address data. Correct data postal standards
Matching or Linking - a way to compare data so that similar, but slightly different records can be aligned. Matching may use "fuzzy logic" to find duplicates in the data. It often recognizes that "Bob" and "Robert" may be the same individual. It might be able to manage "householding", or finding links between husband and wife at the same address, for example. Finally, it often can build a "best of breed" record, taking the best components from multiple data sources and building a single super-record.
Monitoring - keeping track of data quality over time and reporting variations in the quality of data. Software can also auto-correct the variations based on pre-defined business rules.
KID offers Data Cleansing and Data Scrubbing services where we go through a process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database.