KID : MDM Data Profiling and Discovery
Data profiling is an analysis of the candidate data sources for a data warehouse to clarify the structure, content, relationships and derivation rules of the data. Profiling helps to understand anomalies and to assess data quality, but also to discover, register, and assess enterprise metadata.
Master Data Management - Data Profiling Metrics
KID offers data profiling and data discovery services, onsite or as a bureau service.
Reports include:
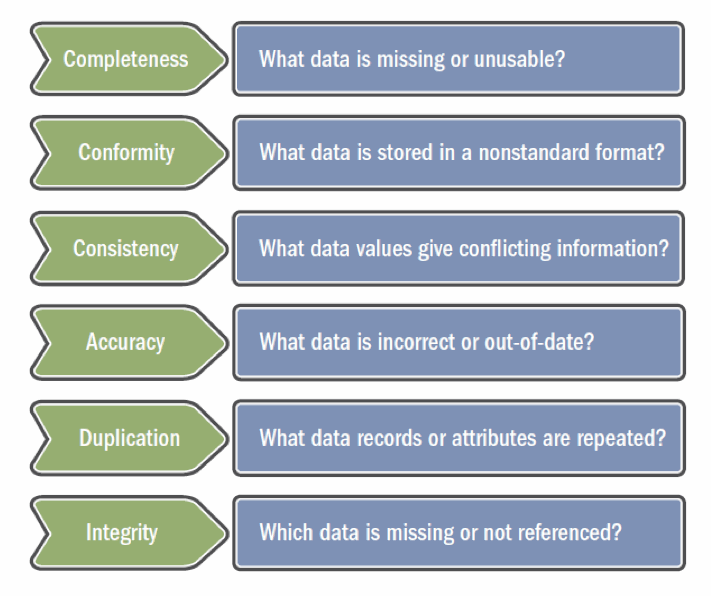
Completeness - Empty or default values in fields
Conformity - content related issues such as incorrect format in field e.g. a name prefix in the customer name field, noise around telephone numbers. Also structure related issues such as field content lengths which are greater than the target structure or inferred data type clashes.
Consistency - look down a column everything looks okay - look across two columns and there's a problem e.g. person coded as a company, company name coded as a person, last invoice date 2 years ago however the customer status being "live". Additional dependencies can be identified with a table or across tables between attributes.
Duplicates records - unique ID, however when you look at the other fields, its obvious that the records are similar enough to be potential duplicates. Similarly duplicate attributes can be identified across tables.
Integrity - associated with relationship e.g. house holding - husband and wife or father and daughter. Additionally referential integrity issues can be identified between tables - e.g. orphan analysis.
Accuracy - comparing data with a reference source - e.g. comparing addresses with the paf, product names with a dictionary, etc.
The benefits of data profiling are to improve data quality, shorten the implementation cycle of major projects, and improve understanding of data for the users.
KID offers Data Profiling services that will assist you in defining the strategy and then implementing the process.